Product Data Cleansing
Data cleansing is the meticulous process of identifying and rectifying (or removing) errors and inconsistencies in data to improve its quality.
Mistakes in product data can lead to significant operational inefficiencies, misinformed decisions, and unsatisfied customers. Ensuring the data’s accuracy and consistency guarantees that your business functions seamlessly.
With our state-of-the-art ML algorithms and a dedicated team of data professionals, we:
Remove Duplicate Entries
Ensure a clean, accurate dataset by eliminating redundant records
Detect & Rectify Poor Language
Refine product descriptions for clarity, professionalism, and impact.
Identify & Add Relevant Missing Data
Fill data gaps with intelligent suggestions based on context and category
Detect & Fix Data Issues
Automatically uncover and resolve inconsistencies or anomalies in your data
Duplicates
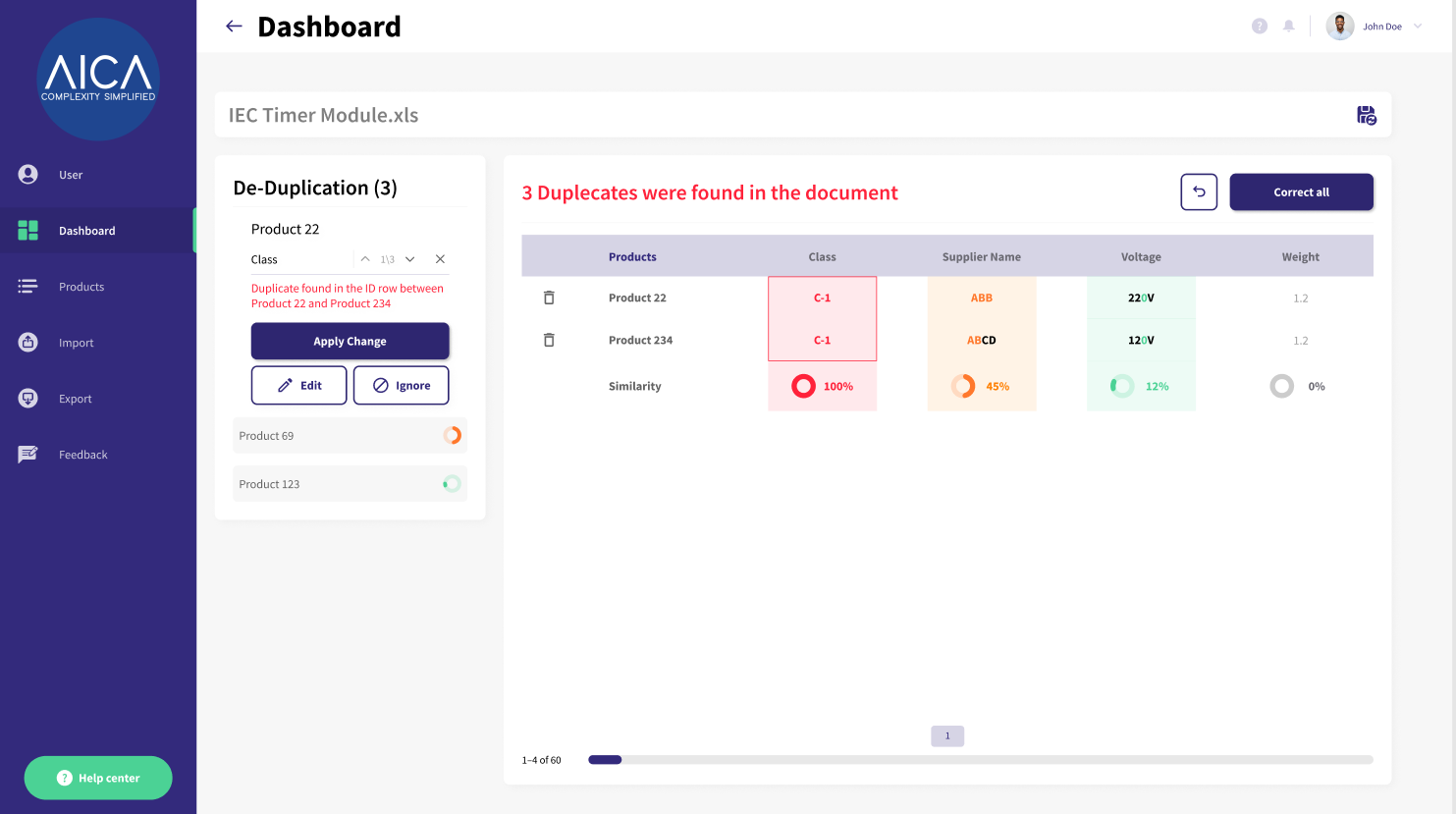
Duplicates refer to two or more identical or very similar entries within a dataset. They can occur in various contexts and for various reasons, but they essentially represent redundant information.
The consequences of duplicate data include:
- Unreliable KPIs
- Increased costs
- Reduction in data integrity
- Operational inefficiencies
Our system searches for duplicate names, descriptions, and numbers on a column and row level.
The user is then given the option to edit, delete, or ignore the duplicates.
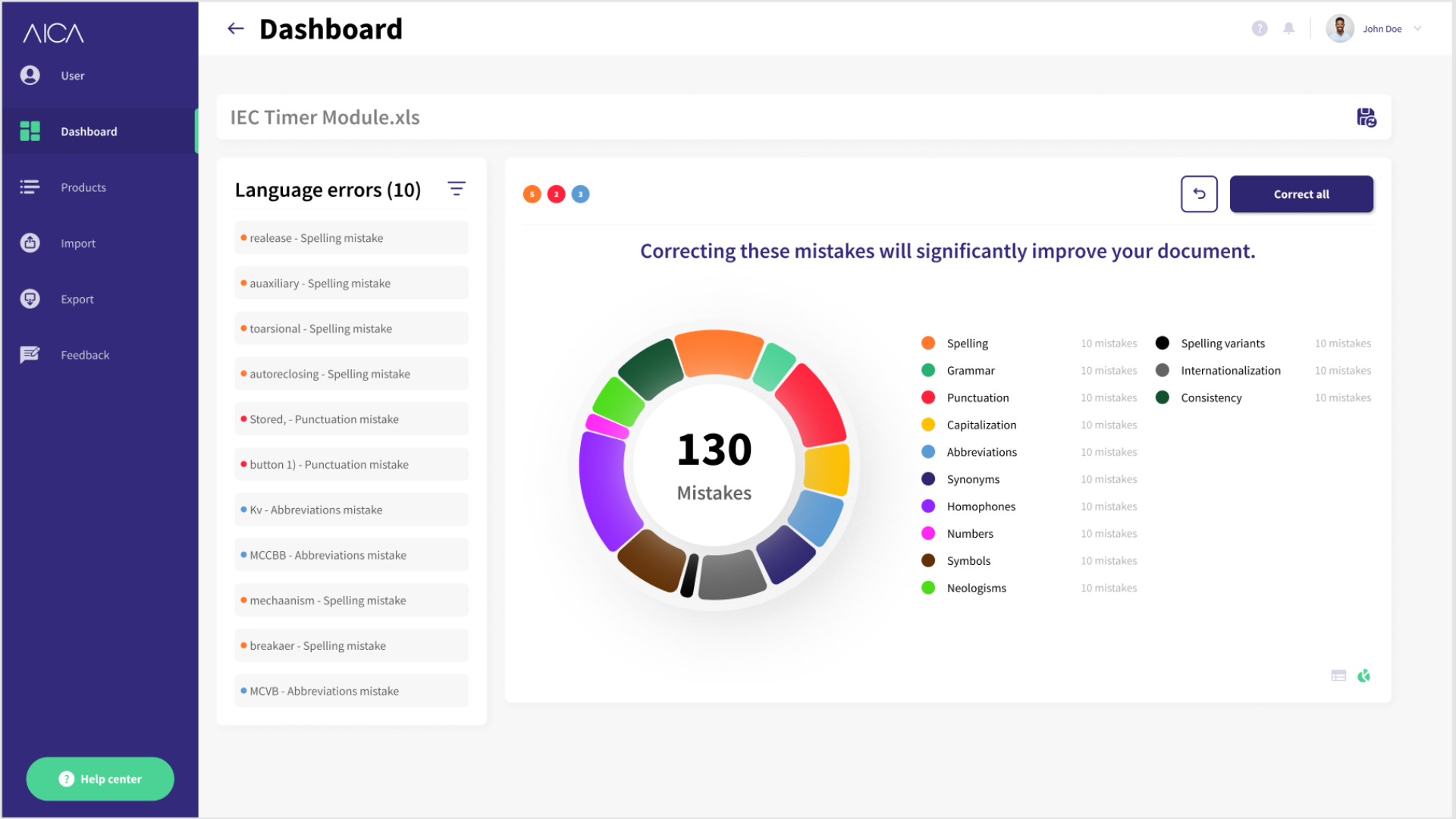
Language
Language refers to the textual and descriptive content associated with products in a dataset. It encompasses all the linguistic information used to describe, categorise and represent products.
The consequences of poor language include:
- Miscommunication
- Operational inefficiencies
- Integration Issues
- Decreased trust and credibility
Language involves the automatic detection of possible spelling and abbreviation errors according to the algorithms.
Our system presents the user with options to correct or ignore the system's suggestions. Uppercase, lowercase, and camel case can all be updated in bulk, and custom spelling in a foreign language can also be requested.
Missing Data
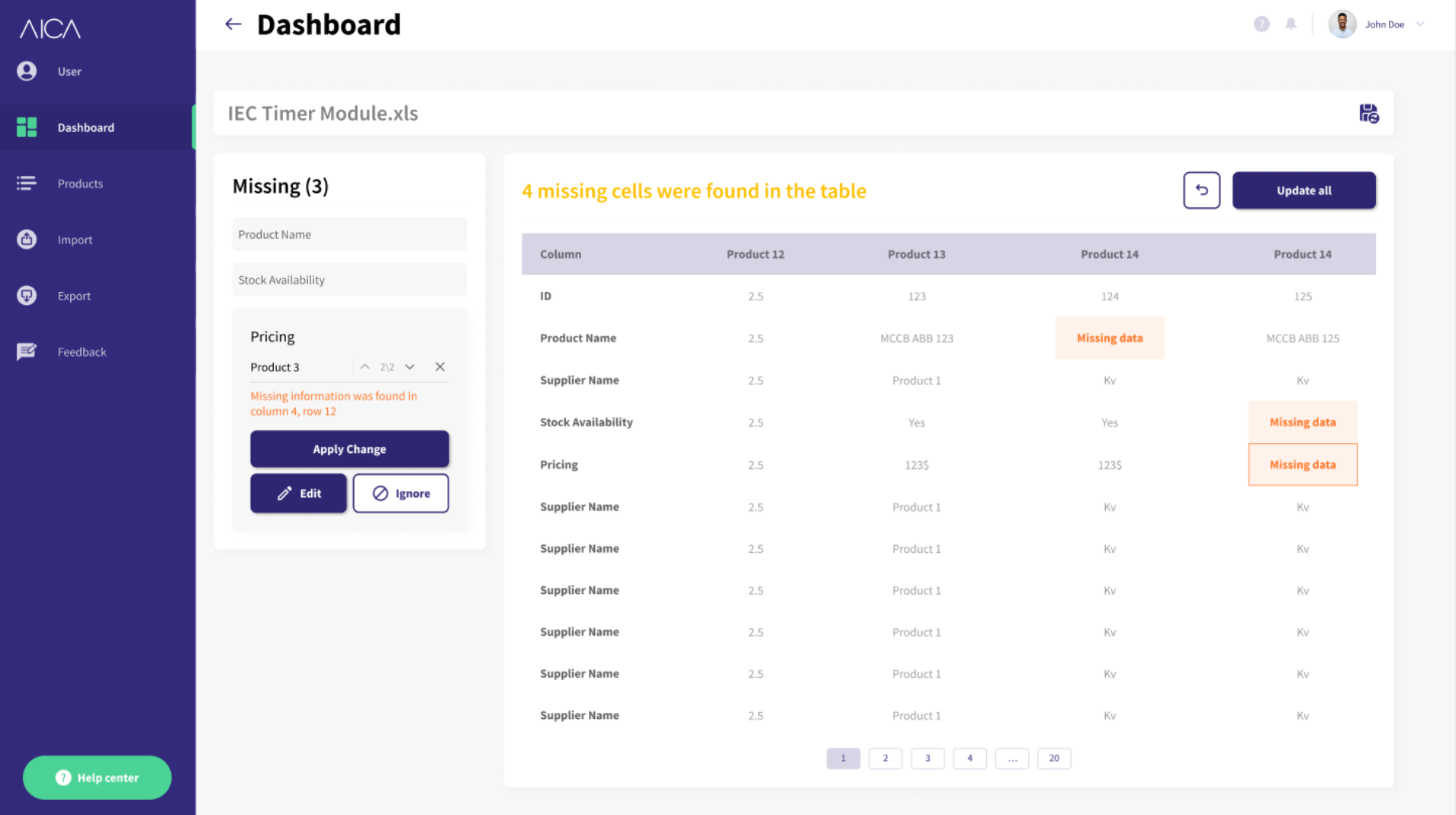
Missing Data or “Data Profiling” identifies blank values, field data types, recurring patterns, and other descriptive statistics for an instant 360-degree view of your data. As an example, a data profile can be useful in identifying opportunities for data cleansing and assessing how well your data is being maintained based on various quality dimensions.
The user can drill down and see which product item records are affected, as well as sort, filter, and conceal information about products.